云计算的三个特点
资源池化
大部分云计算资源,都是池化了的资源。什么叫池化?池化就是物理资源的基础上,通过软件平台,封装成虚拟的计算资源,也就是我们常说的虚拟化。
弹性伸缩
云计算的计算资源,可以按需付费。你想要用多少,就租多少,想什么时候要就什么时候要,配置是支持自定义的。
安全可靠
而云计算,从物理角度来说,所有的计算资源都汇集在大型互联网数据中心(IDC),那里有严格的安保、抗震的建筑、安全的供电,有非常全面的容灾设计和应急方案,能够更好地保护计算资源,不会轻易地中断服务。
从软件上来说,云计算服务提供商有更专业的技术团队,更成熟的技术储备,能够更好地保护计算资源不被入侵或破坏。
云计算服务
应该不考,为了完备性还是放进来吧
- Infrastructure as a Service (IaaS):基础设施即服务
- Platform as a Service (PaaS) :平台即服务
- Software as a Service (SaaS) :软件即服务
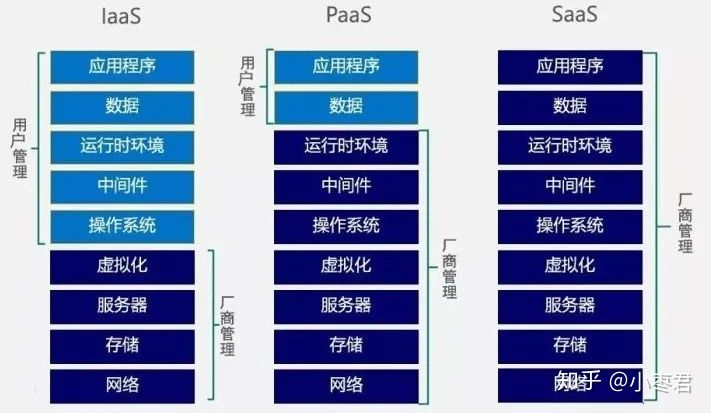
云计算类型
公有云
公有云通常指第三方提供商用户能够使使用的云,公有云一般可通过 Internet 使用,可能是免费或成本低廉的。公有云的最大意义是能够以低廉的价格,提供有吸引力的服务给最终用户,创造新的业务价值,公有云作为一个支撑平台,还能够整合上游的服务(如增值业务,广告)提供者和下游最终用户,打造新的价值链和生态系统。它使客户能够访问和共享基本的计算机基础设施,其中包括硬件、存储和带宽等资源。
公有云是为大众建的,所有入驻用户都称租户,不仅同时有很多租户,而且一个租户离开,其资源可以马上释放给下一个租户。
优点:
缺点:
私有云
是为一个客户单独使用而构建的,因而提供对数据、安全性和服务质量的最有效控制。该公司拥有基础设施,并可以控制在此基础设施上部署应用程序的方式。私有云可部署在企业数据中心的防火墙内(本地私有云),也可以将它们部署在一个安全的主机托管场所(托管私有云)。
优点:
缺点:
社区云
社区云的核心特征是云端资源只给两个或者两个以上的特定单位组织内的员工使用,除此之外的人和机构都无权租赁和使用云端计算资源。与私有云类似,社区云的云端也有两种部署方法,即本地部署和托管部署。
混合云
是两个或两个以上不同类型的云(私有云、社区云、公共云)服务的结合,这种结合可以是计算的、存储的,也可以两者兼而有之。
优点:
- 操作灵活
- 弹性
- 成本效益。混合云模式具有成本效益,因为企业可以根据需要决定使用成本更昂贵的云计算资源。
缺点:
- 安全性不强
- 费用高。 公有云+私有云管理费用高昂
- 兼容性问题
RDD的创建
使用makeRDD即可,例如val rdd = sc.makeRDD(List(1, 2, 3, 4)) 。在使用makeRDD时我们也可以指定分区数量,如val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3),这里我们就创建了3个分区。
当然,除了从程序中创建,我们也可以从文件中读取数据,使用sc.textFile("input")函数来按行读取文件里的数据。如val lineRDD: RDD[String] = sc.textFile("E:\\datas")
Value类型转换算子
map
def map[U: ClassTag](f: T => U ): RDD[U]
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
1
2
3
4
5
6
7
8
9
10
| val rdd = sc.makeRDD(List(1, 2, 3, 4))
def mapFunction(num: Int): Int = {num * 2} //转换函数
val mapRDD1: RDD[Int] = rdd.map(mapFunction)
val mapRDD2 = rdd.map((num: Int) => {num * 2}) //匿名函数
val mapRDD3 = rdd.map((num: Int) => num * 2) //函数的代码逻辑只有一行的时候,{}可省略
val mapRDD4 = rdd.map((num) => num * 2) //参数类型可以推断出来,参数类型可以省略
val mapRDD5 = rdd.map(num => num * 2) //参数列表中的参数只有一个,()可以省略
val mapRDD6 = rdd.map(_ * 2) //参数在逻辑中只出现一次,且顺序出现,参数可用_代替
|
注意要认识最后的简写形式。
mapPartiotions
def mapPartitions[U: ClassTag]( f: Iterator[T] => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]
以分区为单位进行数据转换操作,但是会将整个分区的数据加载到内存进行引用,由于存在对象的引用,因此处理完的数据不会被释放掉。
1
2
3
4
5
6
7
8
| val lineRdd = sc.makeRDD(List(1, 2, 3, 4),2)
val rdd2: RDD[Int] = lineRdd.mapPartitions(
iter => {
println("+++++++++++++++")
iter.map(_ * 2)
}
)
rdd2.collect().foreach(println)
|
结果:
1
2
3
4
5
6
| +++++++++++++++
+++++++++++++++
2
4
6
8
|
上面代码的意思是将每个数据乘以2,并在每次计算时输出+++++,从输出两条+++++可知,mapPartiotions算子确实是按分区进行操作。
map 和 mapPartitions 的区别?
- Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作。
- Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions 算子需要传入一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变, 所以可以增加或减少数据。
- Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高。但是mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。
mapPartitionWithIndex
def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U] ,preservesPartitioning: Boolean = false): RDD[U]
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
1
2
3
4
5
6
7
8
9
10
11
| val lineRdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd2: RDD[Int] = lineRdd.mapPartitionsWithIndex(
(index, iter) => {
if (index == 1) {
iter
} else {
Nil.iterator //Nil是空List
}
}
)
rdd2.collect().foreach(println)
|
结果:
在上面的程序中,我们对第0个分区进行抛弃,对第1个分区进行保留。如所示,程序仅输出了第1分区里的内容。
flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| val lineRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
val groupRDD: RDD[(Int, Iterable[Int])] = lineRdd.groupBy(_ % 2)
groupRDD.foreach(println)
val rdd1: RDD[Int] = groupRDD.flatMap( _._2)
println("Iterable[Int]的flatMap:" + rdd1.collect().mkString(","))
val data2: RDD[List[Int]] = groupRDD.map(_._2.toList)
val rdd2: RDD[Int] = data2.flatMap(t => t)
println("List[Int]的flatMap:" + rdd2.collect().mkString(","))
val lineRdd2 = sc.makeRDD(List(List(1, 2), 3, List(4,5)),2)
val rdd22: RDD[Any] = lineRdd2.flatMap {
case list: List[_] => list
case num: Int => List(num)
}
rdd22.collect().foreach(println)
|
结果:
1
2
3
4
5
6
7
8
9
| (0,CompactBuffer(2, 4))
(1,CompactBuffer(1, 3, 5))
Iterable[Int]的flatMap:2,4,1,3,5
List[Int]的flatMap:2,4,1,3,5
1
2
3
4
5
|
在第一段程序中,我们看出RDD[List]和RDD[iterable]都可以被flaMap算子进行扁平化。在第二段程序中,我们将将 List(List(1,2),3,List(4,5))进行扁平化操作。
重新分区与数据筛选
coalesce
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null): RDD[T]
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。
当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本。
coalesce方法默认情况下不会将分区的数据打乱重新组合,只是将多个分区合并为1一个分区。
1
2
3
4
5
| val rdd = sc.makeRDD(List(1, 2, 3, 4, 5,6),3)
val rdd2: RDD[Int] = rdd.coalesce(2)
//1:1 2
//2:3 4 5 6
|
上面代码的含义是将3个分区缩减成2个,可见成功执行,一个分区里有2个数,而另一个分区里有4个数。
repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的RDD 转换为分区数少的RDD,还是将分区数少的 RDD 转换为分区数多的RDD,repartition 操作都可以完成,因为无论如何都会经 shuffle 过程。
1
2
3
4
5
| val rdd = sc.makeRDD(List(1, 2, 3, 4, 5,6),3)
val rdd2: RDD[Int] = rdd.repartition(2)
//1:1 4 5
//2:2 3 6
|
由于参数 shuffle 的值为 true,将分区的数据打乱重新组合以保证不会出现数据倾斜
distinct
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
将数据集中重复的数据去重
1
2
3
4
5
| val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))
val disRDD = rdd.distinct()
disRDD.collect().foreach(println)
//4 1 3 2
|
filter
def filter(f: T => Boolean): RDD[T]
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡
1
2
3
4
5
| val lineRdd = sc.makeRDD(List(1,2,3,4),2)
val filterRDD: RDD[Int] = lineRdd.filter((num => num % 2 == 0))
filterRDD.collect().foreach(println)
//2 4
|
在上面的程序中,我们过滤掉所有的奇数,仅仅保留偶数
groupBy
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为shuffle。极限情况下,数据可能被分在同一个分区中。
1
2
3
4
5
6
7
8
9
10
| val lineRdd = sc.makeRDD(List(1, 2, 3, 4), 2)
def groupFunction(num: Int): Int = {
num % 2
}
//val groupRDD: RDD[(Int, Iterable[Int])] = lineRdd.groupBy(_ % 2)
val groupRDD: RDD[(Int, Iterable[Int])] = lineRdd.groupBy(groupFunction)
groupRDD.collect().foreach(println)
|
结果:
1
2
| (0,CompactBuffer(2, 4))
(1,CompactBuffer(1, 3))
|
在上面的代码中,按奇偶数进行分组
sortBy
def sortBy[K] ( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原RDD 的分区数一致。中间存在 shuffle 的过程
1
2
3
4
5
6
7
| val rdd = sc.makeRDD(List(("11", 2), ("1", 1), ("2", 3)), 2)
val sortRDD: RDD[(String, Int)] = rdd.sortBy(t => t._1)
sortRDD.collect().foreach(println)
//(1,1)
//(11,2)
//(2,3)
|
上面是字符串排序,按字典序。下面转换成数字,注意两者区别
1
2
3
4
5
6
7
| val rdd = sc.makeRDD(List(("11", 2), ("1", 1), ("2", 3)), 2)
val sortRDD: RDD[(String, Int)] = rdd.sortBy(t => t._1.toInt)
sortRDD.collect().foreach(println)
//(1,1)
//(2,3)
//(11,2)
|
集合类型算子操作
intersection
def intersection(other: RDD[T]): RDD[T]
对源RDD 和参数RDD 求交集后返回一个新的RDD
1
2
3
4
5
6
| val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5,6),3)
val rdd2 = sc.makeRDD(List(1, 2, 3),1)
val rdd3 = rdd1.intersection(rdd2)
rdd3.collect().foreach(println)
//3 1 2
|
union
def union(other: RDD[T]): RDD[T]
对源RDD 和参数RDD 求并集后返回一个新的RDD
1
2
3
4
5
6
| val rdd1 = sc.makeRDD(List(1, 2, 3))
val rdd2 = sc.makeRDD(List(4, 5, 6))
val rdd3 = rdd1.union(rdd2)
rdd3.collect().foreach(println)
//1 2 3 4 5 6
|
subtract
def subtract(other: RDD[T]): RDD[T]
以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集
1
2
3
4
5
6
| val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
val rdd2 = sc.makeRDD(List(4, 5, 6))
val rdd3 = rdd1.subtract(rdd2)
rdd3.collect().foreach(println)
//1 2 3
|
zip
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的Key 为第 1 个 RDD中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
1
2
3
4
5
| val rdd1 = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd2 = sc.makeRDD(List(3, 4, 5, 6), 2)
val zipRDD: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(zipRDD.collect().mkString(","))
//(1,3),(2,4),(3,5),(4,6)
|
- 如果两个RDD 数据类型不一致 ,对于交集,并集,差集,两个RDD的数据类型必须相同。对于拉链操作,两个RDD的数据类型可以不同。
- 如果两个RDD的分区中数据量不一致,对于交集,并集,差集,两个RDD的分区中数据量不需要相同;对于拉链操作分区中数据量必须相同。
Key-Value类型算子
reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
可以将数据按照相同的Key 对Value 进行聚合,聚合操作是两两进行聚合的。reduceByKey中如果key的数据只有一个,是不会参与运算的。
1
2
3
4
5
| val rdd: RDD[(String)] = sc.makeRDD(List("Hello Scala", "Hello Spark", "Hello Spark", "Hello 123"),2)
val wordRDD: RDD[String] = rdd.flatMap(_.split(" "))
val wordOneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
val result: RDD[(String, Int)] = wordOneRDD.reduceByKey(_ + _)
result.collect().foreach(println)
|
结果:
1
2
3
4
| (Hello,4)
(123,1)
(Scala,1)
(Spark,2)
|
在上面的代码中,根据参数_+_,即表示将两个value进行相加。
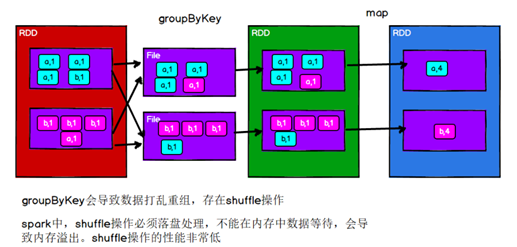
groupByKey
def groupByKey(): RDD[(K, Iterable[V])]
将数据源的数据根据 key, 对 value 进行分组,将数据源中相同key的数据分在一个组中,行成一个对偶元祖,元组中的第一个元素就是key,元组中的第二个元素就行相同key的value的集合。
1
2
3
4
5
6
| val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1), ("b", 1), ("b", 1), ("b", 1), ("a", 1)), 2)
val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
groupRDD.collect().foreach(println)
//(b,CompactBuffer(1, 1, 1, 1))
//(a,CompactBuffer(1, 1, 1, 1))
|
aggregateByKey
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
将数据根据不同的规则进行分区内计算和分区间计算。
aggregateByKey存在函数柯里化,有两个参数列表。
第一个参数列表,需要传递一个参数,表示初始值。主要用于当碰见第一个key的时候,和value进行分区内计算。
第二个参数列表需要传递两个参数
- 参数2.1:分区内的计算规则
- 参数2.2:分区间的计算规则
1
2
3
4
5
6
7
8
9
10
11
| val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
//同分区获取最大值,不同分区相加求和
val rdd2: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
)
rdd2.collect().foreach(println)
//(b,8)
//(a,8)
|

foldByKey
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为foldByKey
1
2
3
4
5
6
7
8
| val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
//同分区相加求和,不同分区相加求和
val rdd2: RDD[(String, Int)] = rdd.foldByKey(0)(_ + _)
rdd2.collect().foreach(println)
//(b,12)
//(a,9)
|
combineByKey
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
对key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
combineByKey方法需要三个参数
- 第一个参数:表示将相同key的第一个数据进行结构的转换,实现操作
- 第二个参数:表示分区内的计算规则
- 第三个参数:表示分区间的计算规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
val rdd2: RDD[(String, (Int, Int))] = rdd.combineByKey(
(t) => (t, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val rdd3: RDD[(String, Int)] = rdd2.map {
case (str, (t1, t2)) => {
(str, t1 / t2)
}
}
rdd3.collect().foreach(println)
//(b,4)
//(a,3)
|
在上面的例子中,首先将相同key的格式转为(t,1),分区内计算对于第一个数据进行相加,第二个数据+1,分区间将第一和第二个数据对应相加。

join
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
在类型为(K,V)和(K,W)的RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的RDD
两个RDD中的元素对进行笛卡尔乘积性质的匹配,但只会打印出匹配成功的。
1
2
3
4
5
6
7
8
| val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)), 2)
val rdd2 = sc.makeRDD(List(("b", 5), ("a", 4), ("c", 6)), 2)
var joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
//(b,(2,5))
//(a,(1,4))
//(c,(3,6))
|
在上面的例子里,成功将a,b,c后面的值合在一起了
如果两个数据源中有多个相同的key,那么数据源a中的key会与数据源b中相同的key多次匹配成功,因此会数据量会几何性质增长
1
2
3
4
5
6
7
| val rdd1 = sc.makeRDD(List(("a",1), ("b", 2),("c", 3)),2)
val rdd2 = sc.makeRDD(List(("b", 5), ("d",4), ("b", 6)),2)
var joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
//(b,(2,5))
//(b,(2,6))
|
leftOuterJoin
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
类似于 SQL 语句的左外连接,根据左边第一个元素将两个RDD连接起来,和join算子类似,但这个可以支持key不匹配的情况。
1
2
3
4
5
6
7
8
9
| val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)), 2)
val rdd2 = sc.makeRDD(List(("a", 5), ("b", 4)), 2)
val leftJoinRDD: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
leftJoinRDD.collect().foreach(println)
//(b,(2,Some(4)))
//(a,(1,Some(5)))
//(c,(3,None))
|
1
2
3
4
5
6
7
8
9
10
11
| val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)), 2)
val rdd2 = sc.makeRDD(List(("a", 5), ("b", 4), ("b", 5), ("b", 6)), 2)
val leftJoinRDD: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
leftJoinRDD.collect().foreach(println)
//(b,(2,Some(4)))
//(b,(2,Some(5)))
//(b,(2,Some(6)))
//(a,(1,Some(5)))
//(c,(3,None))
|
rightOuterJoin
类似于左外连接,两者区别在于左连接是以左边的RDD为主,右连接以右边的RDD为主。
1
2
3
4
5
6
7
8
9
| val rdd1 = sc.makeRDD(List(("a",1), ("b", 2)),2)
val rdd2 = sc.makeRDD(List(("a", 5), ("b",4),("c", 3)),2)
val rightJoinRDD: RDD[(String, (Option[Int], Int))] = rdd1.rightOuterJoin(rdd2)
rightJoinRDD.collect().foreach(println)
//(b,(Some(2),4))
//(a,(Some(1),5))
//(c,(None,3))
|
行动算子
reduce
def reduce(f: (T, T) => T): T
聚集RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据
1
2
3
4
5
| val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 聚合数据
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
//10
|
在上面的例子中,10=1+2+3+4
collect
def collect(): Array[T]
在驱动程序中,方法会将不同分区的数据按照分区顺序采集到Driver端内存中,形成数组。
1
2
3
4
5
| val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//收集数据到Driver
rdd.collect().foreach(println)
//1 2 3 4
|
first
def first(): T
返回RDD 中的第一个元素
1
2
3
4
| val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val firstResult: Int = rdd.first()
println(firstResult)
//1
|
take
def take(num: Int): Array[T]
返回一个由RDD 的前 n 个元素组成的数组
1
2
3
4
5
| val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
//1,2
|
takeOrdered
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
返回该 RDD 排序后的前 n 个元素组成的数组
1
2
3
4
| val rdd: RDD[Int] = sc.makeRDD(List(1, 3, 2, 4))
val result: Array[Int] = rdd.takeOrdered(2)
result.foreach(println)
//1 2
|
aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合;即,初始值不仅参与分区内计算,同时也参与分区间计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
/*
* 组内:
* 初值10,分区1(1),组内结果11
* 初值10,分区2(2),组内结果12
* 初值10,分区3(3),组内结果13
* 初值10,分区4(4),组内结果14
* 初值10,分区5(0),组内结果10
* 初值10,分区6(0),组内结果10
* 初值10,分区7(0),组内结果10
* 初值10,分区8(0),组内结果10
*
* 组间:
* 初值10,分区(11,12,13,14,10,10,10,10),结果100
*/
val result: Int = rdd.aggregate(10)(_ + _, _ + _)
println(result)
//100
|
fold
def fold(zeroValue: T)(op: (T, T) => T): T
折叠操作,aggregate的简化版操作
1
2
3
4
| val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_ + _)
println(foldResult)
//10
|
countByKey
def countByKey(): Map[K, Long]
统计每种 key 的个数
1
2
3
4
5
| val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
// 统计每种 key 的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
//Map(1 -> 3, 2 -> 1, 3 -> 2)
|
RDD 依赖关系
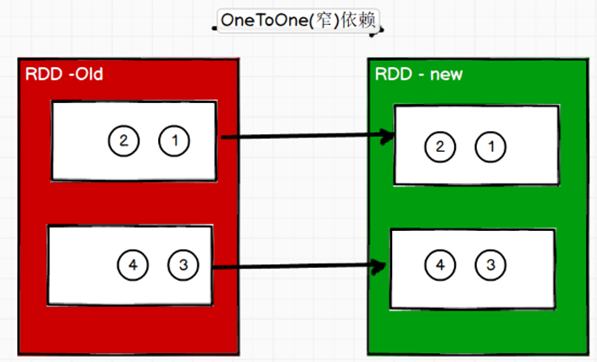
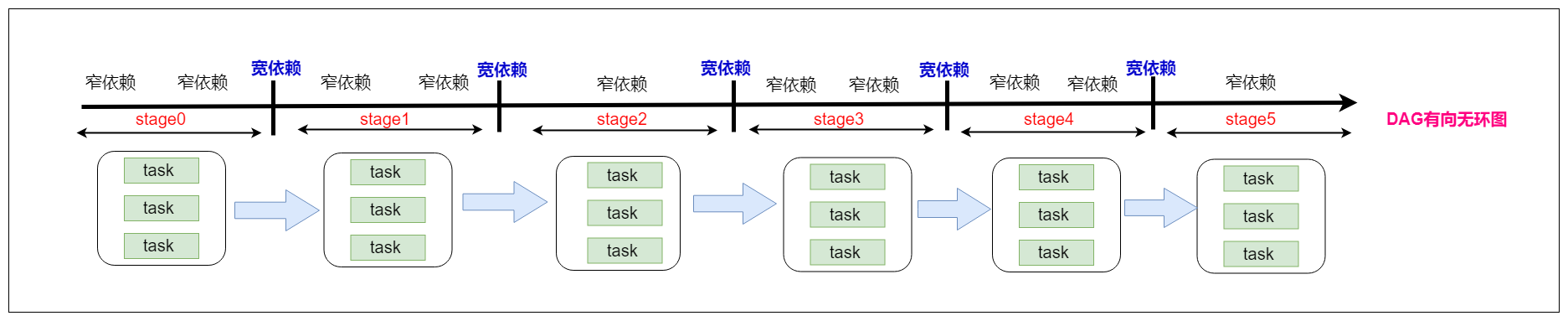
窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
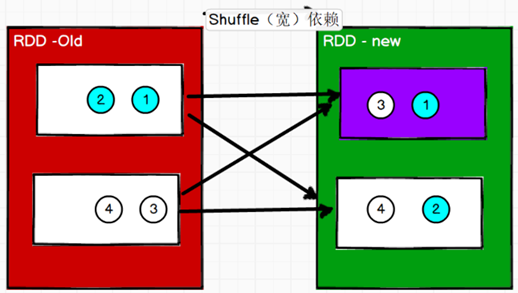
宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
WordCount
典中典程序,必考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("spark-core/src/main/resources/words")
val wordRDD: RDD[String] = rdd.flatMap(_.split(" "))
val wordOneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
val result: RDD[(String, Int)] = wordOneRDD.reduceByKey(_ + _)
result.collect().foreach(println)
//关闭连接
sc.stop();
}
}
|
有向无环图
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG。
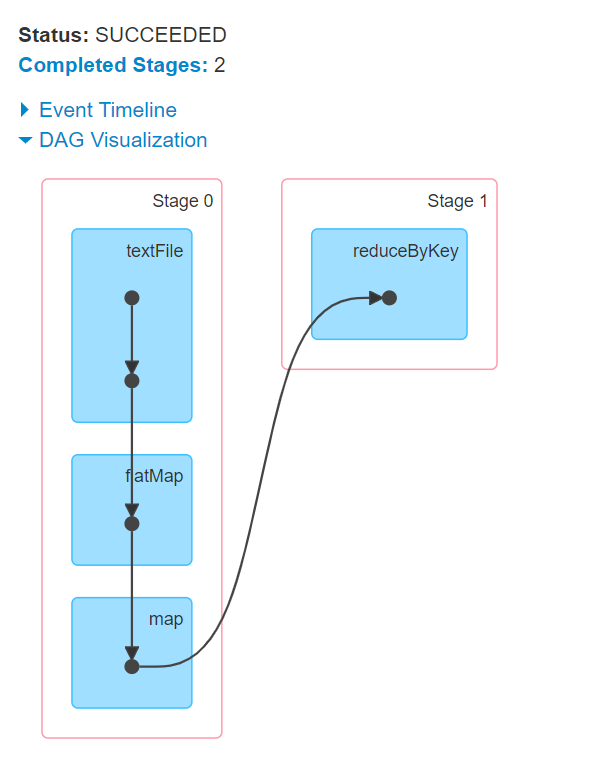
stage的划分
一个Job会被拆分为多组Task,每组任务被称为一个stage。stage表示不同的调度阶段,一个spark job会对应产生很多个stage。
根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)
- 对于窄依赖,partition的转换处理在一个Stage中完成计算
- 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算
划分stage的依据就是宽依赖
- 首先根据rdd的算子操作顺序生成DAG有向无环图,接下里从最后一个rdd往前推,创建一个新的stage,把该rdd加入到该stage中,它是最后一个stage。
- 在往前推的过程中运行遇到了窄依赖就把该rdd加入到本stage中,如果遇到了宽依赖,就从宽依赖切开,那么最后一个stage也就结束了。
- 重新创建一个新的stage,按照第二个步骤继续往前推,一直到最开始的rdd,整个划分stage也就结束了
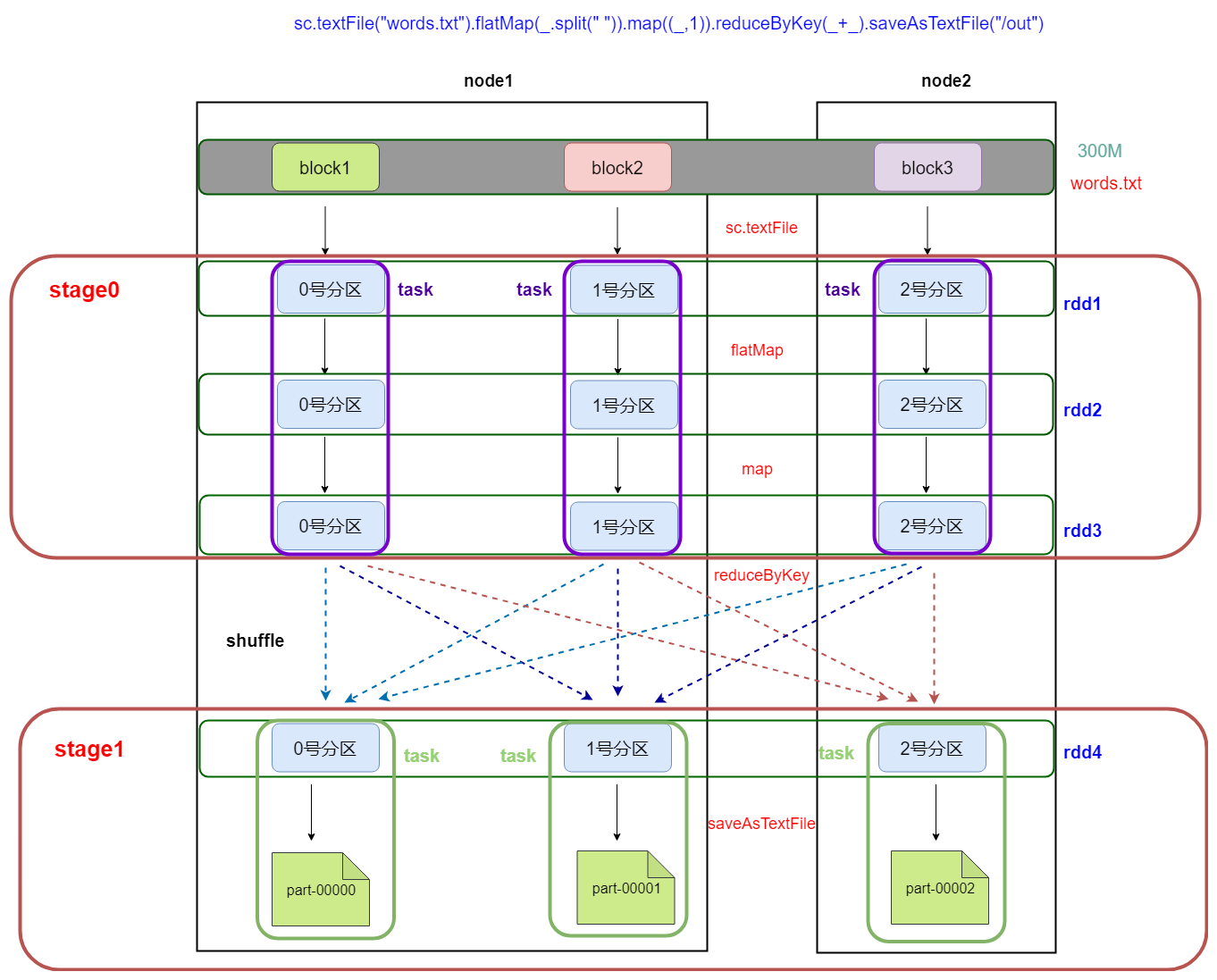
划分完stage之后,每一个stage中有很多可以并行运行的task,后期把每一个stage中的task封装在一个taskSet集合中,最后把一个一个的taskSet集合提交到worker节点上的executor进程中运行。
rdd与rdd之间存在依赖关系,stage与stage之前也存在依赖关系,前面stage中的task先运行,运行完成了再运行后面stage中的task,也就是说后面stage中的task输入数据是前面stage中task的输出结果数据。
缓存和检查点区别
必考,也是非常重要
- Cache 缓存只是将数据临时保存起来。Cache 缓存的数据通常存储在内存,可靠性低。不切断血缘依赖,只会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据。
- persisit:将数据临时存储在磁盘文件中进行数据重用,涉及到磁盘IO,性能较低,但是数据安全。如果作业执行完毕,临时保存的数据文件就会丢失。
- CheckPoint:将数据长久地保存在磁盘文件中进行数据重用,涉及到磁盘IO,性能较低,但是数据安全。为了包装数据安全,所以一般情况下,会独立执行作业,就是把当前需要持久化的RDD重新创建并保存。为了能够提高效率,通常和cache联合使用。
- Checkpoint 检查点会切断血缘依赖,重新建立新的血缘关系。
- cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。但 checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。 也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用checkpoint() 的时候,建议加上 rdd.cache(), 这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。建议对checkpoint()的RDD 使用Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次RDD。Checkpoint 检查点切断血缘依赖。
combineByKey和aggregateByKey的异同
相同点
- 都有三个参数
- 第二个和第三个参数都是分区内操作和分区间操作
- 都属于聚合操作,使数据量减少
- 都是转换算子,不触发程序执行
不同点
- 对于第一个参数,aggregateByKey是设置初始值,combineByKey是进行转换
- combineByKey组内计算和组间计算数据格式不一样;
aggregateByKey组内计算和组间计算数据格式一样
aggregate和aggregateByKey的异同
相同点
不同点
- aggregateByKey的初始值不会参与分区间计算;对key进行操作,需要键值对
- aggregate的初始值会参与分区间计算,会触发程序运行,进行读数据
求平均值
典中典程序,这也是必考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object exam {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("exam");
val sc = new SparkContext(sparkConf)
val lineRdd: RDD[(String, Int)] = sc.makeRDD(List(("Spark", 5), ("Hadoop", 3), ("Scala", 4), ("Spark", 3), ("Hadoop", 1)))
val rdd1: RDD[(String, (Int, Int))] = lineRdd.map(t => (t._1, (t._2, 1)))
val rdd2: RDD[(String, (Int, Int))] = rdd1.reduceByKey((t, k) => ((t._1 + k._1), (t._2 + k._2)))
val rdd3: RDD[(String, Int)] = rdd2.map(
t => (t._1, t._2._1 / t._2._2)
)
rdd3.collect().foreach(println)
sc.stop()
}
}
|
算子补充
glom
def glom(): RDD[Array[T]]
将同一个分区的数据直接转换为一个相同类型的内存数组进行处理,分区不变
1
2
3
4
5
| val lineRdd = sc.makeRDD(List(1, 2, 3, 4),2)
val glomRDD: RDD[Array[Int]] = lineRdd.glom()
glomRDD.collect().foreach(data => println(data.mkString(",")))
//1,2
//3,4
|
sample
def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]
根据指定的规则从数据集中抽取数据
- 第1个参数withReplacement表示:抽取后是否将数据返回,true(放回),false(丢弃)
- 第2个参数fraction表示: 当第一参数为true,第二个参数表示:抽取不放回的概率;基准值的概念(每个数有一个0~1随机值,用随即值与基准值进行比较); 当第一个参数为false,第二个参数表示,可能抽取的次数。
- 第3个参数seed表示:抽取数据时,随机算法的种子;如果不传第三个参数,那么使用的当前系统时间
1
2
3
4
5
6
7
8
9
10
11
12
13
| val dataRDD = sparkContext.makeRDD(List( 1,2,3,4),1)
// 抽取数据不放回(伯努利算法)
// 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子
val dataRDD1 = dataRDD.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val dataRDD2 = dataRDD.sample(true, 2)
|
partitionBy
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
将数据按照指定的Partitioner规则 重新进行重新分区。Spark 默认的分区器是HashPartitioner
太冷门了,应该不考,就不放代码了
cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
在类型为(K,V)和(K,W)的RDD 上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的 RDD
1
2
3
4
5
6
7
8
9
10
| val rdd1 = sc.makeRDD(List(("a",1), ("b", 2), ("x", 44)),2)
val rdd2 = sc.makeRDD(List(("a", 5), ("b",4),("c", 3), ("c", 99)),2)
val cgRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
//(x,(CompactBuffer(44),CompactBuffer()))
//(b,(CompactBuffer(2),CompactBuffer(4)))
//(a,(CompactBuffer(1),CompactBuffer(5)))
//(c,(CompactBuffer(),CompactBuffer(3, 99)))
|
下面都是行动算子
count
def count(): Long
返回RDD 中元素的个数
saveAsTextFile
def saveAsTextFile(path: String): Unit
保存成 Text 文件
1
| rdd.saveAsTextFile("output")
|
