
介绍
在大数据时代,机器学习(ML)为我们的生活提供了便利,并在各个领域发挥着不可或缺的作用。随着深度学习应用场景的丰富和数据的增长,主流云提供商(如谷歌、亚马逊和微软)推出了机器学习即服务(MLaaS)。
MLaaS
顾名思义,MLaaS是一系列提供机器学习工具作为云计算服务一部分的服务。 这些服务的主要吸引力在于,就像其他任何云服务一样,客户无需安装软件或配置自己的服务器即可快速开始机器学习。它帮助资源和专业知识有限的数据所有者(小型企业或个人)解决数据处理、模型训练和评估等基础设施问题。模型提供者通过根据查询时间向用户收费来获得收益。
然而,MLaaS却容易受到模型提取攻击的影响。如下图所示,虽然模型托管在安全的云服务中,客户通过基于云的API进行查询。但是,攻击者可以基于预测输出来训练具有目标私有模型类似功能的替代模型。用户可以通过访问替代模型而无需向模型提供者付费,从而破坏了其商业价值。此外,攻击者还可以利用替代模型来制作优秀的可转移对抗性示例,从而有效地欺骗原始模型做出错误的预测,构成严重的安全威胁。
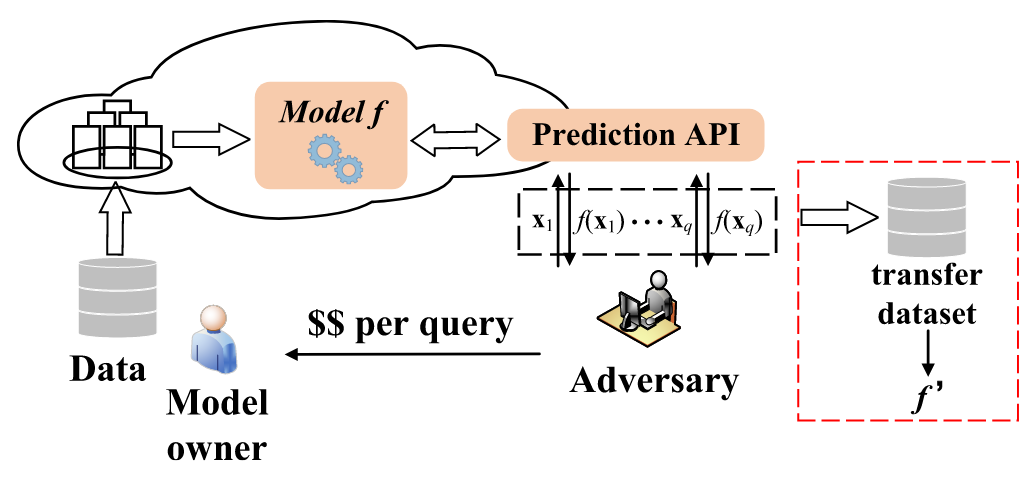
作者提出了APMSA来防御模型提取攻击。当攻击者窃取服务器中部署的 “model under attack” (MUA) 时,通过发散给定特定类别的特征空间中查询样本的置信向量距离,就会泄露足够的MUA内部信息,有利于替代模型的训练。对此,作者在MUA 之前将微妙的噪声注入每个传入的输入查询中,以限制其置信向量的多样性。
相关研究
目前,将对于模型提取攻击的防御通常可分为两类:被动防御和主动防御。 前者是被动地检测恶意查询行为,然后限制或拒绝为更可能来自攻击者的恶意传入查询提供推理服务。 后者主要是指主动置信扰动技术。本文介绍的APMSA属于主动防御技术,作者将相关的文章进行了整理,如下表所示。
- Model extraction warning in MLaaS paradigm
- PRADA: Protecting against DNN model stealing attacks
- Defending against model stealing attacks with adaptive misinformation
- Defending against neural network model stealing attacks using deceptive perturbations
- BODAME: Bilevel optimization for defense against model extraction
- Prediction poisoning: Towards defenses against DNN model stealing attacks
- Model stealing defense with hybrid fuzzy models: Work-in-progress
与现有的直接置信扰动技术相比,APMSA不仅保留了MUA的可用性,还保留了MUA的实用性。与其他主动防御相比,APMSA可以简单地在MUA之前插入,而无需对MUA本身进行任何修改,因此它是通用的,易于部署的。
贡献
- 通过建设性地最小化对训练替代模型至关重要的发散置信度信息来禁用被盗模型的可用功能。
- 通过形式化的优化实现了置信向量对 MUA 决策边界的限制。
- APMSA不会对具有硬标签推理的普通用户造成效用损失
问题构造
威胁模型
假设攻击者不了解系统的模型体系结构。攻击者只能通过迁移学习发起攻击,即攻击者使用恶意样本查询黑盒模型,以标记这些将用于训练替代模型的样本。攻击者从公众中识别预训练模型,并基于预训练模型通过迁移学习构建替代模型;训练数据集是通过 MUA 上的查询的一组输入输出对。具体算法如下:

攻击者只能通过 API 与模型交互,查询次数受预算限制。但是,他们可以自由选择任何样本进行查询(即未标记的公共数据集$X_{pub}$)。因此,攻击者完全了解输入(即样本类型)和输出(即标签集)的特征。但是,攻击者只能观察返回的预测置信向量,而不能观察模型架构和梯度信息。
攻击者旨在获得与私有模型$f$具有相似功能的替代模型$f’$。替代模型$f’$在公共数据集 $\mathbf{S}\subseteq\mathbf{X}_{pub}$ 的子集上进行训练:
$$f^{\prime}\approx\arg\min\mathcal{L}\left(\{(\mathbf{x},f(\mathbf{x})):\mathbf{x}\in\mathbf{S}\},f^{\prime}(\mathbf{x})\right)$$防御者旨在将噪声注入每个查询的输入中,以间接干扰模型返回的预测。APMSA有两个主要目标。一方面,保留了模型的精度,即不使用APMSA时的精度应与原始精度相同。另一方面,被盗模型的准确性在很大程度上被破坏,使攻击者的免费私人查询不再有效。作者将使用 APMSA 前后模型准确性的下降程度作为指标。
APMSA的概述
APMSA的直觉是如果防御者策略性地混淆输入查询与其返回的置信度(向量)的输出之间的映射关系,则当攻击者利用这样的输入-输出对来训练其替代模型时,对攻击者有用的泄漏信息将被最小化甚至误导。
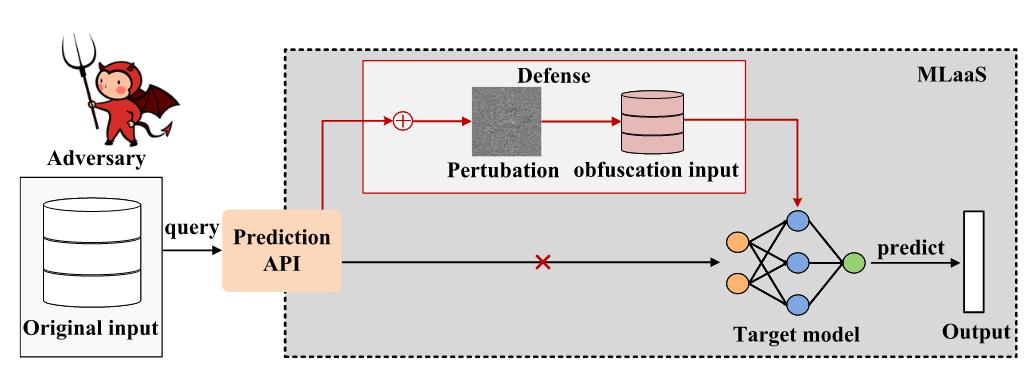
上图是APMSA的流程。当向API查询输入时,APMSA不直接将该输入馈送到模型并返回置信向量。 相反,APMSA通过将对抗性噪声扰动注入到输入中来将该输入转换为对抗性输入。模型最终返回的是变换后的对抗性输入相对应的置信度向量。从攻击者的角度来看,其输入与返回的置信向量之间的关系映射已经被混淆。并且将给定类别样本的置信度向量约束在一个小的区域内,从而大大减少了泄漏信息,便于其替代模型的训练。同时,由于APMSA不会修改输入的硬标签,所以对于普通用户来说性能几乎没有损失。值得注意的是,APMSA是作为插件使用,不需要修改模型。
APMSA的实现
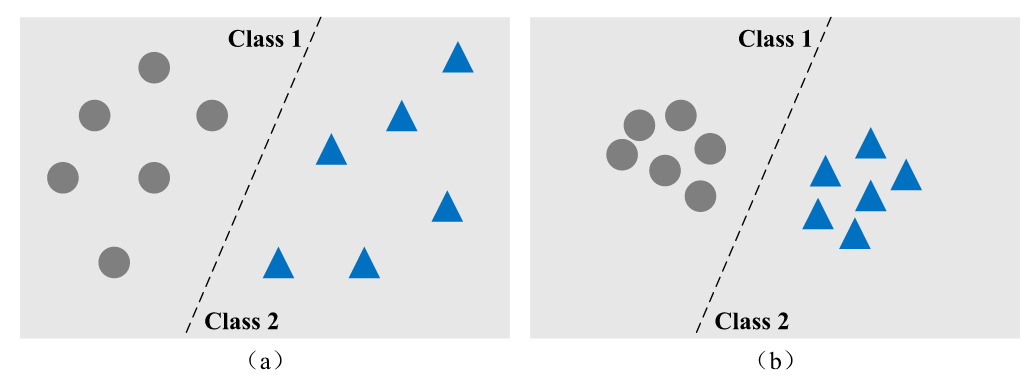
作者在此用一个例子来解释了APMSA。假设有一个二分类模型(性别分类),如果模型将$k$个男性类别的图像映射到$k$个不同的概率分布,则在给定不同分布的情况下,$k$个输入-输出对的映射关系将揭示更多关于模型的内部信息。 (如图a所示)但是,如果控制$k$个不同的男性图像映射到特征空间中的相邻区域,则泄露的信息将大大减少。 此外,这些混淆的输入-输出对将在很大程度上误导训练替代模型。(如图b所示)
也就是说如果输出都堆在一起,就可以混淆输入和输出之间的关系,并且可以更好地保护模型的隐私。
作者随后介绍了APMSA的详细原理。同样是以二分类的模型为例,$f$是原模型,$f’$是攻击者得到的替代模型。其中,攻击者利用查询$x$来获得预测$y=f(x)$,其中$y=\{y_1,y_2\}$,攻击者使用$(x,y)$来训练替代模型。APMSA则是通过将向输入空间中的$x$添加对抗性噪声来将样本$x$变为混淆样本$x_c$。这里应用了制作对抗性样本$x’$的技术。与$x’$不同的是,$x_c$的硬标签与APMSA中的$x$的硬标签相同。这样,攻击者通过$\{x,y_c=f(x_c)\}$训练出来的模型$f’$决策边界就会导致$x_t$被误分类,从而防止模型窃取攻击。
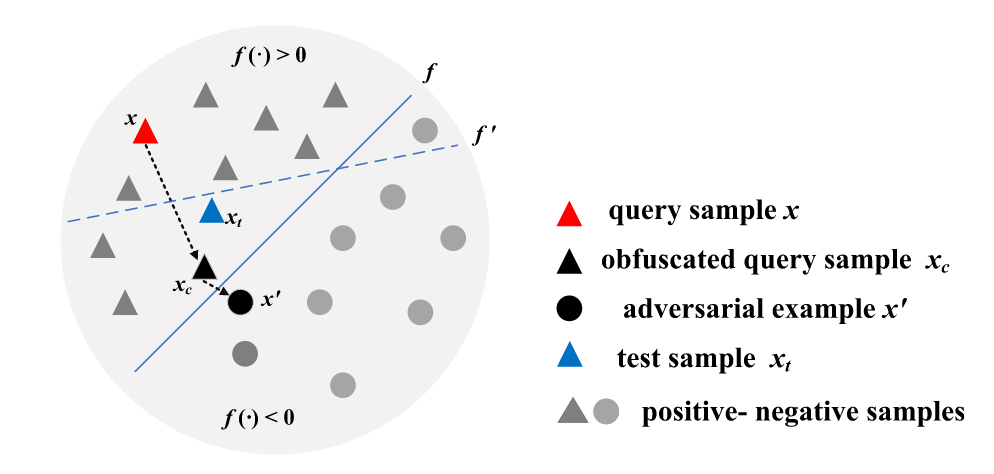
与传入的查询输入$x$相比,经变换的对抗输入$x_c$接近决策边界。作者将其转化成了一个优化问题:
- 混淆的输入$x’$与其对应的对抗示例$x_c$在特征空间中相似,但$x_c$的硬标签与原始输入$x$的类别相同
- 混淆输入$x_c$和原始输入$x$的置信向量之间的间隙应尽可能小
将其公式化表示为:
$$\begin{aligned}\mathcal{L}_1&=J\left(\mathbf{x}_c\right)=J(\mathbf{x}+\delta)\\&=\min_\delta\max\left(Z(\mathbf{x}+\delta)_s-Z(\mathbf{x}+\delta)_t,0\right)\end{aligned}$$其中$Z(x_c)_t$表示目标类别$t$的对数值,$Z(x_c)_s$表示原类别$s$。
如果使$Z(x_c)_s-Z(x_c)_t$变小,就表明指定类别的对数值和源类别之间的差距越来越大,则混淆输入$x_t$更接近目标类别的对抗样本。作者提出了新的约束来提高优化速度。
$$\begin{cases}\mathcal{L}_2=Clip_{(0,\infty)}\left(\max\left\{Z(\mathbf{x}+\delta)_i:i\neq t,o\right\}-Z(\mathbf{x}+\delta)_t\right)\\ \mathcal{L}_3=Clip_{(0,\infty)}\left(\max\left\{Z(\mathbf{x}+\delta)_i:i\neq t,s\right\}-Z(\mathbf{x}+\delta)_s\right)\end{cases}$$其中$Clip(·)$表示范围约束。
为了确保 APMSA 不会影响模型的性能(即标签不会更改),优化目标是:
$$\begin{aligned} \mathcal{L}_{4}& =\text{distance }(\mathbf{y},\mathbf{y}_c)=\min_\delta\|\mathbf{y}-\mathbf{y}_c\| \\ &=\min_\delta\|f(\mathbf{x})-f(\mathbf{x}+\delta)\| \end{aligned}$$这是为了测量扰动输入前后的置信差,以减轻APMSA对模型效用对普通用户的影响。综上,可以得到优化函数:
$$\begin{aligned}\mathcal{L}&=\mathcal{L}_1+c_1\cdot\mathcal{L}_2+\mathcal{L}_3+c_2\cdot\mathcal{L}_4\\&=\min_\delta J(\mathbf{x}+\delta)+c_1\cdot\mathcal{L}_2+\mathcal{L}_3+c_2\cdot\|f\left(\mathbf{x}\right)-f\left(\mathbf{x}+\delta\right)\|\end{aligned}$$其中超参数$c_1$和$c_2$用于正则化损失函数,在实验中根据经验分别设置为2和0.01。 优化过程不是要找到对抗性样例,而是要识别以正确保存类别为条件的接近其对应对抗性样例的混淆输入$x_c$。
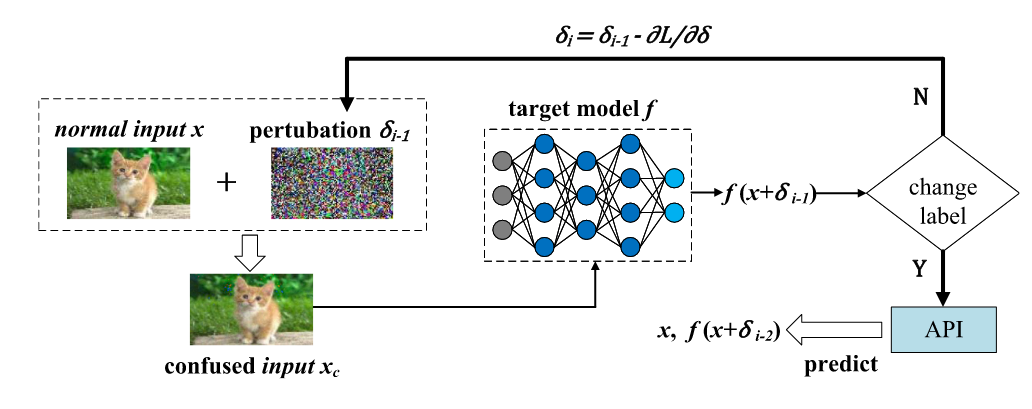
APMSA的具体过程如下:

实验评价
数据集:
- CIFAR10
- GTSRB
评估指标:
- Top-1 精度
模型提取攻击评估
选择VGG16作为攻击者初始替代模型的模型结构。使用学习率为 0.0001 的 SGD 来最小化均方误差的损失。
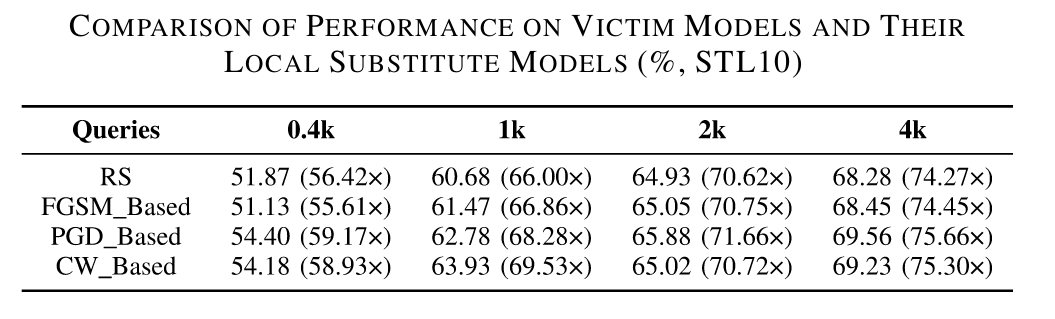
使用CIFAR-10数据集训练了一个基于ResNet-18的模型,准确率为91.94%,并在不应用防御的情况下部署。 对于初始替代模型,作者选择了在ImageNet上预训练的VGG 16模型,并使用STL 10数据集作为公共查询样本。
放宽限制,将查询样本设置为 CIFAR10 测试集的一小部分进行查询。
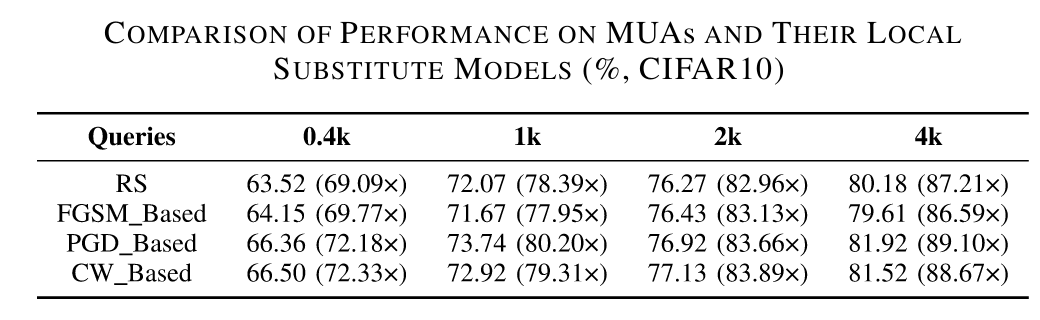
使用GTSRB数据集训练了一个基于ResNet-18的MUA模型,准确率为95.40%,并在不应用防御的情况下部署。 对于初始替代模型,选择了在ImageNet上预训练的VGG 16模型。
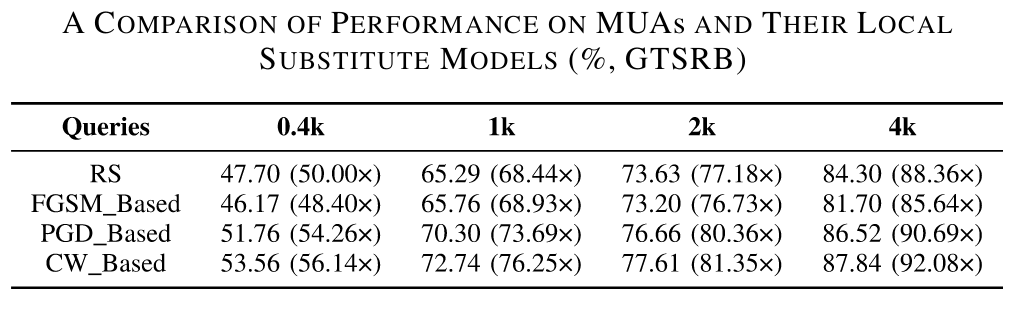
上述案例表明:
- 查询样本的选择会影响模型窃取攻击的效率。具体来说,更接近目标域数据分布的查询样本始终有利于攻击。
- 基于决策边界的样本合成技术(即通过PGD、CW)可以提供比随机查询更有用的信息。
- 随着查询预算的增加,基于决策边界的样本生成并没有带来太大的性能提升。原因可能是所选样本分布与原始模型的训练集过于接近,基于决策边界的样本结构提供的信息量相对有限。
- 当样本数量较少时,基于迁移学习的模型窃取攻击可提高攻击效果。原因是样本越少,冗余信息越少。然而,由于获得的信息相似,更多的查询样本可能会导致信息冗余,这不会为促进攻击提供更多有用的信息。
作者进一步评估攻击者选择的不同替代模型架构对攻击效果的影响。替代模型的性能受所选模型架构的影响。如图所示,VGG16始终表现出优于CIFAR10其他模型的攻击性能。
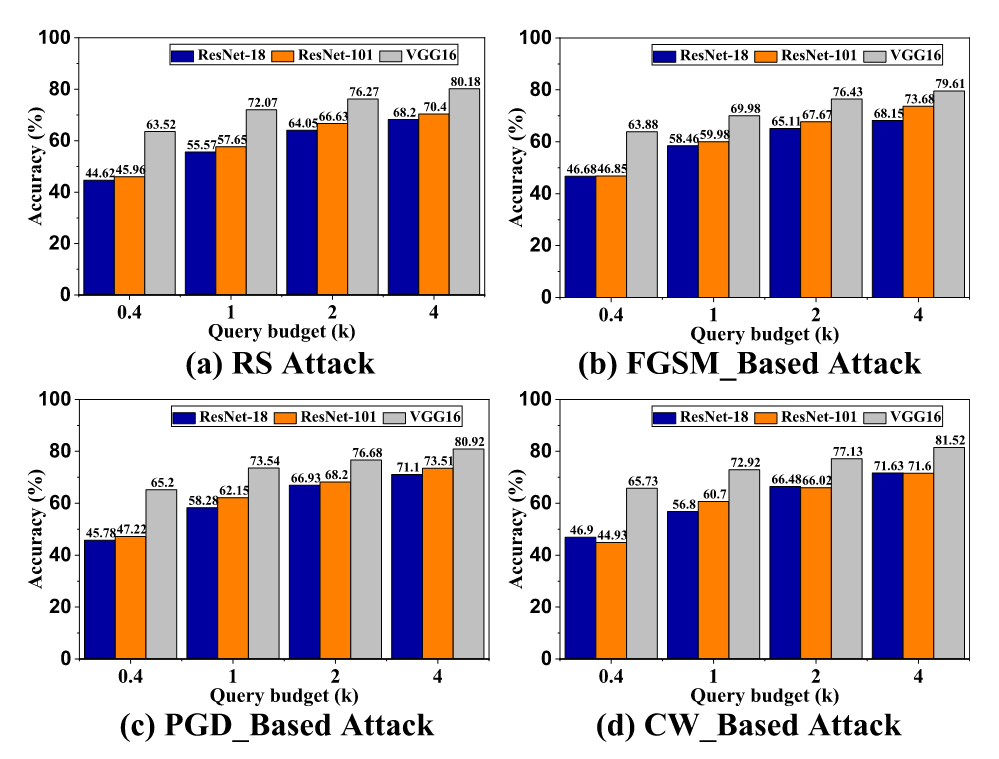
同样,在在GTSRB数据集上评估时,ResNet50表现出最好的攻击效果,略好于VGG16,使用AlexNet的性能最差。这表明选择合适的替代模型可以降低攻击成本。
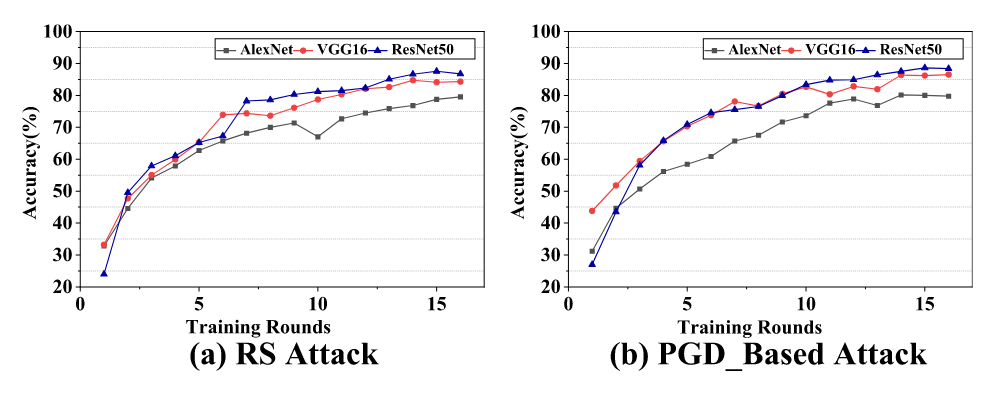
综上,查询样本的选择会影响模型窃取攻击的效率和替代模型的准确性。具体来说,攻击最好选择类似于目标域的数据分布的公共查询样本。
此外,基于决策边界的样本合成技术(PGD、CW等)可以提供比随机查询更有用的信息。但是,随着查询次数的增加,基于决策边界的样本并没有带来太大的性能提升。原因可能是所选样本分布与原始模型的训练集太接近。
防御验证
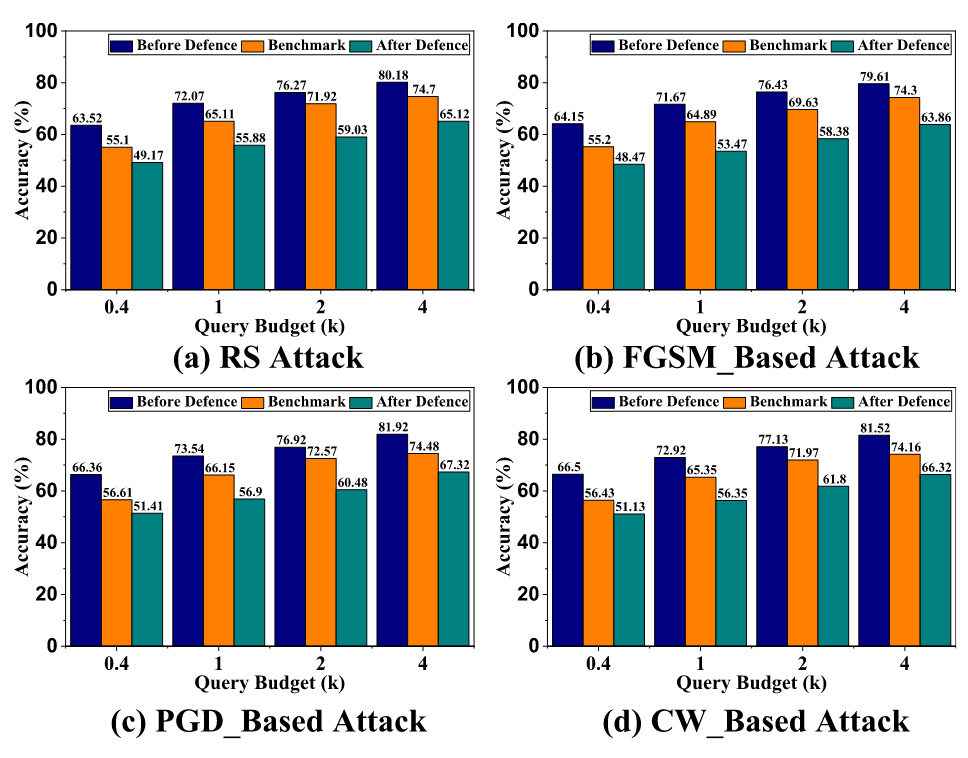
使用APMSA后,替代模型的准确率甚至低于基准,表明防御减少了模型预测引起的模型内部信息泄露。
APMSA的关键见解是,通过将输入映射到特征空间的小尺度区域,可以尽可能减少输入输出对携带的信息泄漏,甚至在很大程度上产生误导性信息。为了可视化这一关键见解,作者使用 t-SNE 和归一化操作来减少用于可视化的混淆输入的维度。
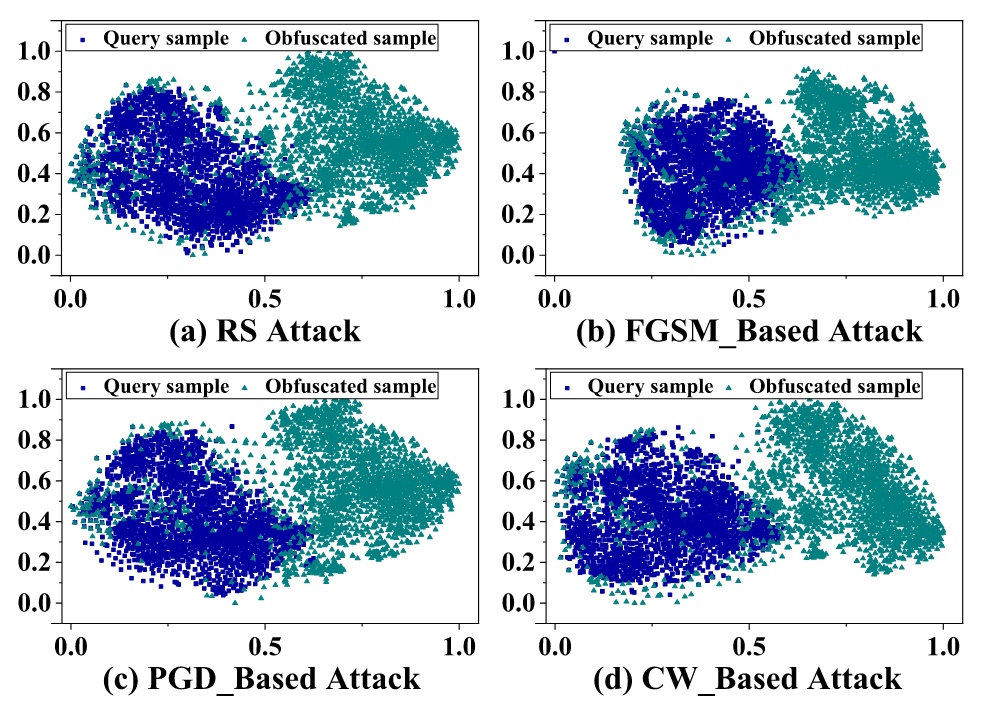
CIFAR10 数据集上的混淆输入和查询样本之间存在明显的分离——每个混淆输入都是从传入的查询样本中找到的。在将原始查询样本与混淆输出相关联时,通过干扰模型预测中泄露的信息,以减少模型窃取攻击的影响。